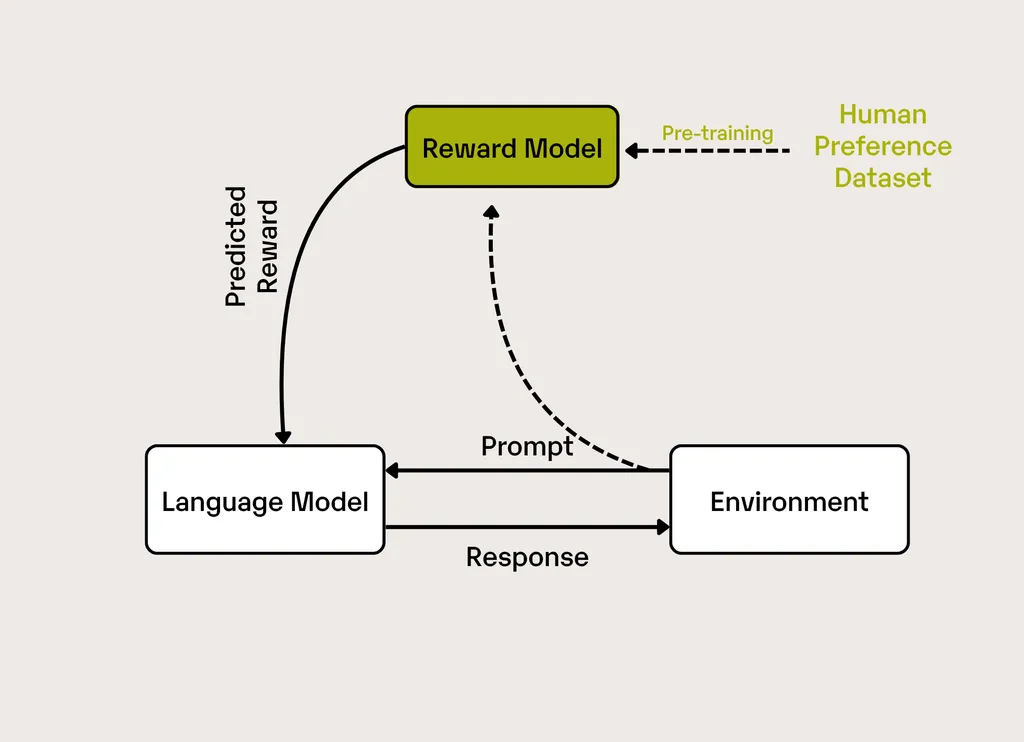
Researchers Franklin Cardenoso and Wouter Caarls have introduced a groundbreaking framework designed to streamline the process of creating effective reward functions in reinforcement learning (RL). Their work, titled “LEARN-Opt (LLM-based Evaluator and Analyzer for Reward functioN Optimization),” addresses a critical bottleneck in RL by leveraging large language models (LLMs) to automate the generation and optimization of reward functions.
The challenge of designing reward functions in RL has long been a significant hurdle, often demanding extensive human expertise and considerable time. Previous efforts to automate this process have relied on preliminary evaluation metrics, human-engineered feedback, or environmental source code as context. LEARN-Opt, however, eliminates these dependencies. This innovative framework operates autonomously and is model-agnostic, meaning it does not require preliminary metrics or environmental source code. Instead, it generates, executes, and evaluates reward function candidates based solely on textual descriptions of systems and task objectives.
The core contribution of LEARN-Opt lies in its ability to autonomously derive performance metrics directly from system descriptions and task objectives. This capability enables unsupervised evaluation and selection of reward functions, significantly reducing the need for human intervention. The researchers’ experiments demonstrate that LEARN-Opt achieves performance comparable to or better than state-of-the-art methods like EUREKA, while requiring less prior knowledge. This highlights the potential of LLMs to automate complex tasks in RL, thereby reducing engineering overhead and enhancing generalizability.
One of the key findings from their research is that automated reward design is a high-variance problem. This means that while many candidates may fail, a multi-run approach is necessary to identify the best-performing ones. LEARN-Opt’s ability to handle this variability makes it a robust tool for optimizing reward functions. Additionally, the framework showcases the potential of low-cost LLMs to find high-performing candidates that are comparable to, or even better than, those generated by larger models.
The implications of this research are profound for the maritime sector, where RL can be applied to optimize various operational tasks. For instance, autonomous vessels could benefit from optimized reward functions that enhance navigation efficiency, reduce fuel consumption, and minimize environmental impact. By automating the design of these functions, LEARN-Opt could accelerate the development and deployment of advanced RL applications in maritime operations, leading to more efficient and sustainable practices.
In summary, Franklin Cardenoso and Wouter Caarls’ work on LEARN-Opt represents a significant advancement in the field of reinforcement learning. By leveraging the power of LLMs, they have developed a framework that not only simplifies the process of designing reward functions but also enhances the performance and generalizability of RL models. This innovation holds great promise for various industries, including maritime, where the optimization of operational tasks is crucial for efficiency and sustainability. Read the original research paper here.